完全メモ, 非厳密, 無益です。
カーネル・シェル・ターミナル・コンソールとは
歴史的に厳密にはニュアンスの違い等があるらしいが, 現代ではカーネルを除いて殆ど同じ意味で使われているし, 違いを明確に知る必要もないらしい。また, OS文化圏によっても定義のされ方が異なるらしいし, ネットで調べてもきちんと理解できないので諦めました。ということで全部cmd.exeみたいなやつだと思っています。
カーネル:
OSの中’核’。CPU, メモリ, マウス・キーボード等の入出力デバイスを管理し, 実際に操る。OSに内包される。
シェル:
カーネルとユーザの橋渡し役, ユーザーはシェルを通してカーネルに命令を送る。ユーザーが直接カーネルを触れないようにするための’殻’的なイメージ。抽象化が行われてユーザが扱いやすくなる。
ex. sh, bash(shの進化系, 多くのLinuxのデフォルト), zsh(現代的), cmd.exe, windows powershell
ターミナル
ユーザがコンピュータへ入出力する際に使うハードウェア。例えば入力: キーボード, 出力: ディスプレイ。現代ではハードウェアとしてのターミナルは使われず, ターミナルをソフトとして実装したターミナルエミュレータ・仮想ターミナルの意味で使われる事が多い。
コンソール
よく分かりません。
シェルスクリプトとは
シェルを操作するためのスクリプト言語。シェルでの操作を組み合わせて自動化できる。
以下, Windows PowerShellを用いる。
現状Windowsしか使わないので, これが良さそう。
スクリプトに関するドキュメント: (https://docs.microsoft.com/ja-jp/powershell/scripting/samples/sample-scripts-for-administration?view=powershell-7.1)
やりたいこと
特定言語での操作はある程度できるようになったので, 異なるプログラミング言語同士を連携させたい。
例えば, “Heuristic系のプログラミングコンテストで複数のテストをC++に実行させて, 出た解を採点, 点数の総和 or 平均をとる”ようなことをやりたい。
今回はこれを目標にする。手順は次のとおりである。
- C++のソースをコンパイルする
- 実行させる
- (ループ毎に異なる)入力を与える
- 結果を受け取る
- (もし採点が別に必要な場合は採点する)
- 2~5を繰り返す
- 点数の総和 or 平均を出力
順にやっていく。
- C++のソースをコンパイルする
g++ A.cpp -o B -W -std=c++17
AというC++のソースをB.exeという実行ファイルにコンパイルする。-o Bは実行ファイル名の指定, -Wは警告の許可, -std=c++17はバージョンの指定。
2. 実行させる
3. (ループ毎に異なる)入力を与えるcat C.txt | .\B.exe
C.txtを標準入力としてB.exeを実行する。実行ファイルを指定する場合.\を付けて現在のディレクトリだと指定する必要がある。’|’は左側の出力を右側のコマンドの入力とするみたい。
4. 結果を受け取る(今回はB.exeの出力がスコアであるとする)$score += cat C.txt | .\B.exe
5. (もし採点が別に必要な場合は採点する)
今回は省略。
6. 2~5を繰り返すfor ($i = 0; $i -lt 上限; $i++){処理}
通常のforループ, <が-ltになるので注意。foreach ($変数 in $変数){処理}
範囲for
7. 点数の総和 or 平均を出力echo $score
で出力ができる。
以上を用いて作成したコード
1 | $score = 0 |
これを適当な名前.ps1(Powershellのスクリプトの拡張子)というテキストファイルに突っ込んで, ソースと同じディレクトリに配置, テストケースを.txtで.\TestCaseに配置して実行するとできます!
実は↑のコードはAHC002(https://atcoder.jp/contests/ahc002/tasks/ahc002_a)用に書いたのですが, うまくいきました!別のコンテストでも簡単にできそうです。
今後の課題
- 採点用のコードがrust等で配布された場合にそのコンパイル・実行もやる
- ヒューリスティックコンテストでは制限時間指定をするため(2s等), シングルスレッド?でやるとかなり時間がかかる。マルチスレッド対応?させると良さそう。
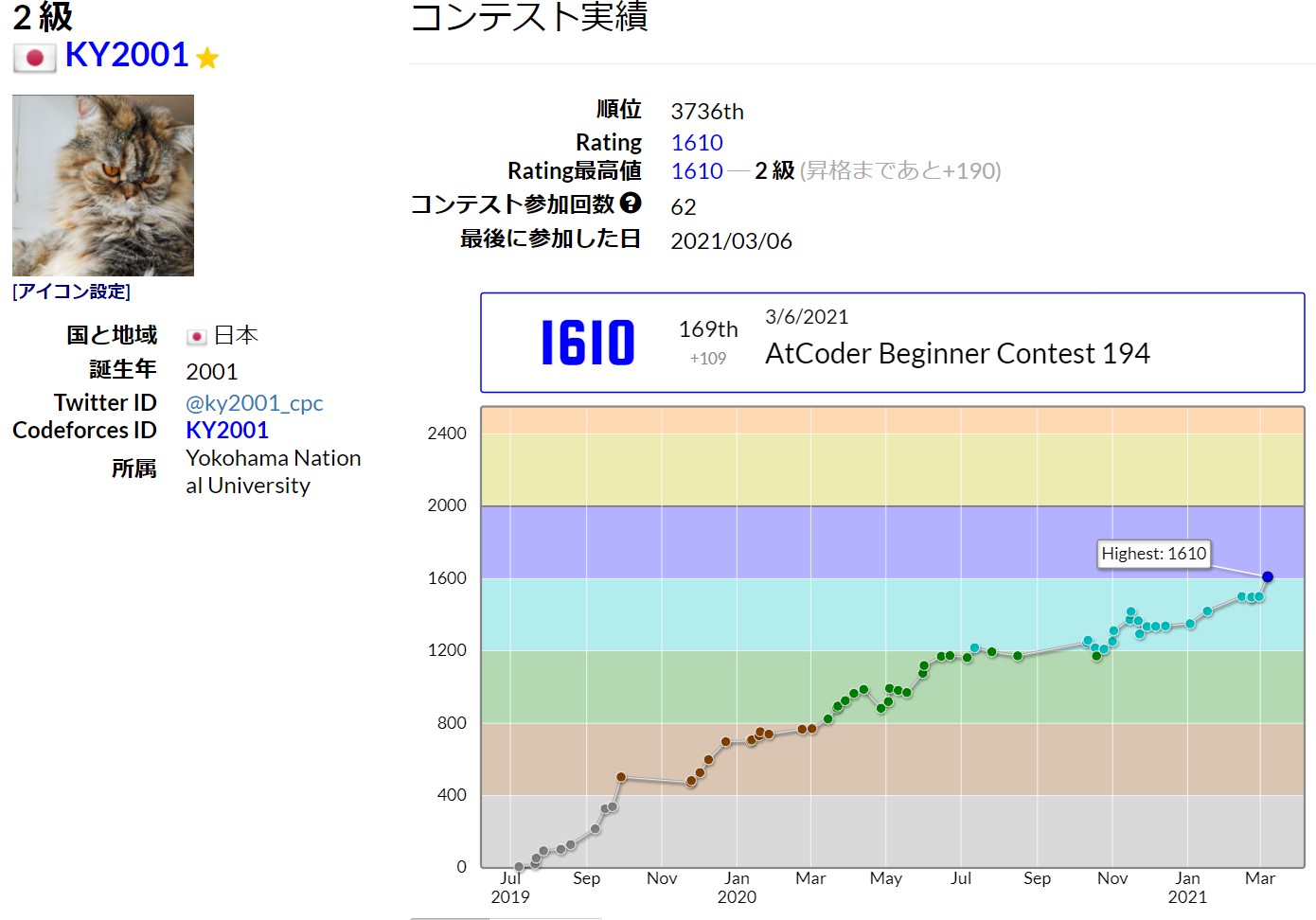
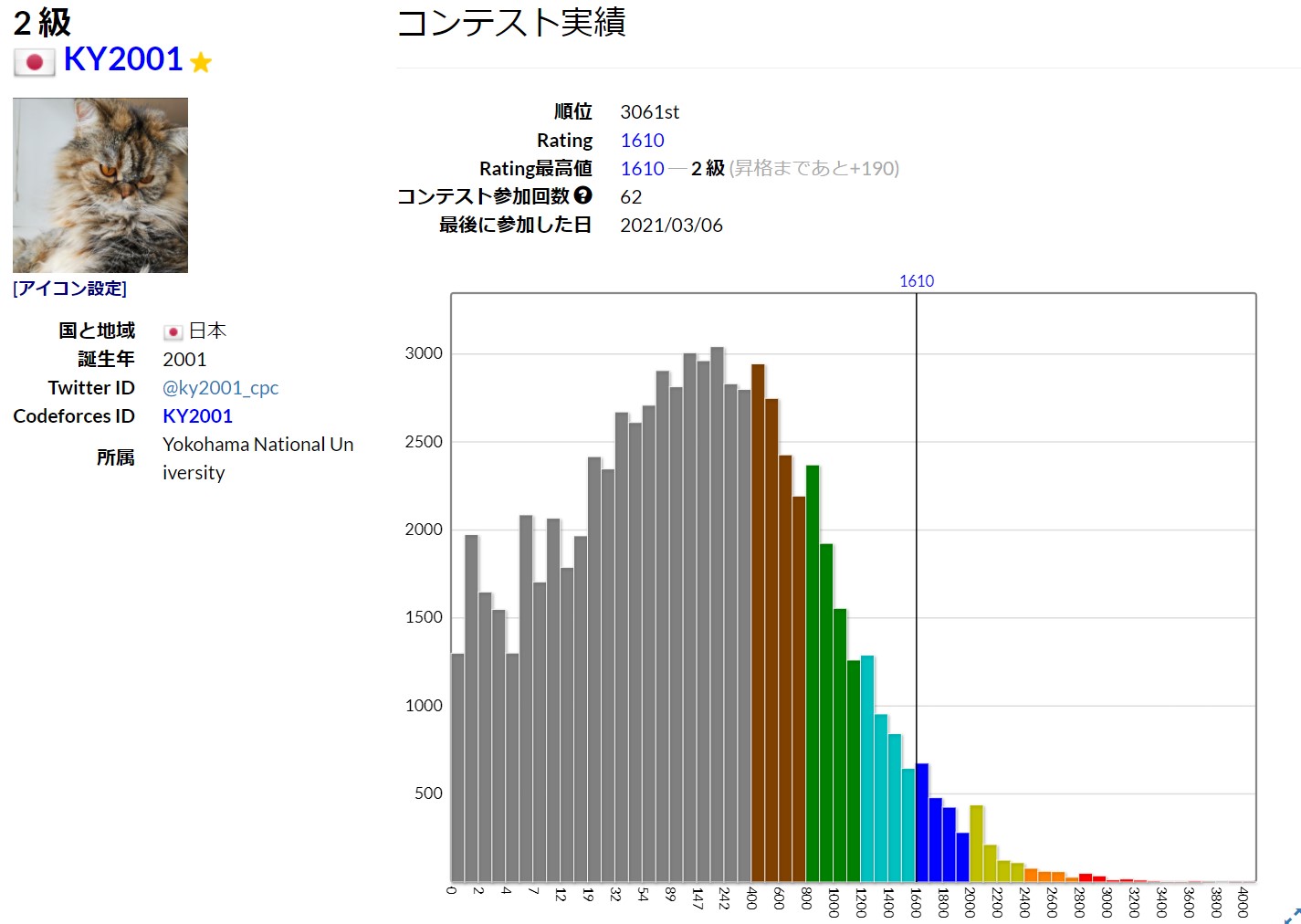

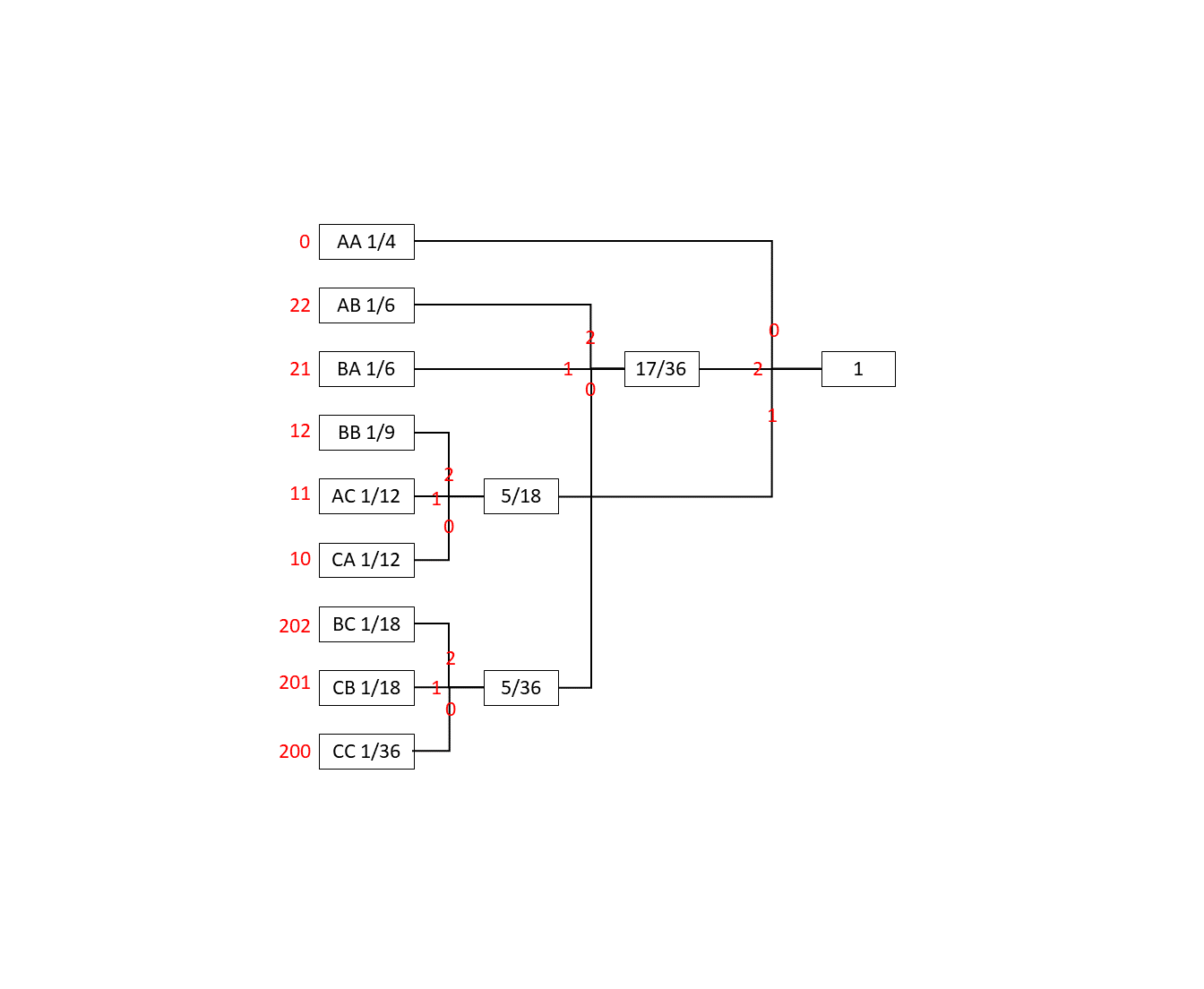
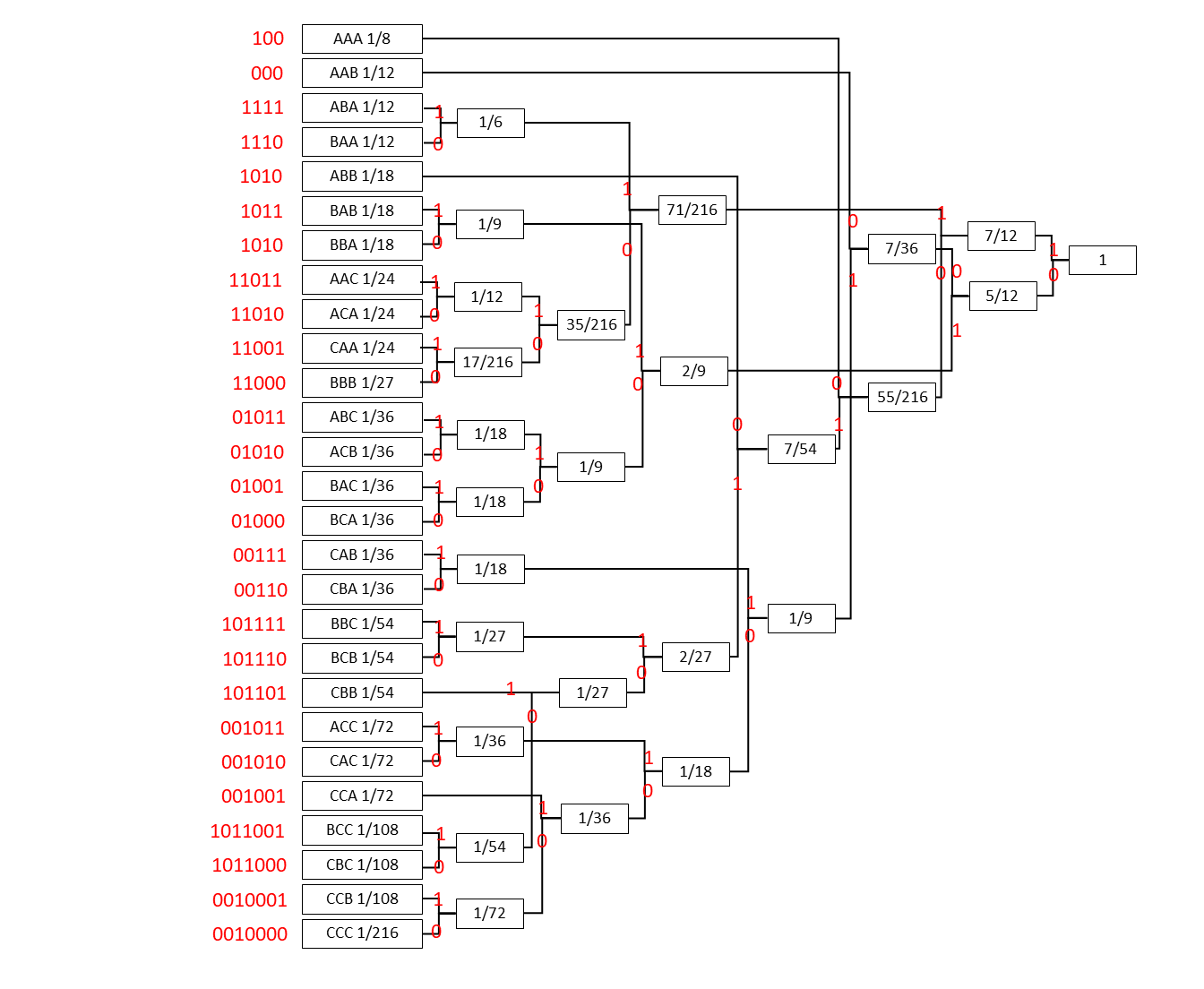
 平均符号長
平均符号長