ハフマン符号化
情報源記号を符号化する際に, 平均符号長を最小にするような符号化の方法の1つをハフマン符号化という.
m元ハフマン符号化のアルゴリズム
- 各情報源記号に対応する葉をつくる.
- 今ある中で確率の最も小さいm個の葉を子とする新たな葉をつくる.
- 葉の数がm個未満になるまで1, 2を繰り返す.
- m個未満の今ある全ての葉を子とする根をつくる.
- 根から部分木の確率の総和が小さい順に0…m-1を割り当てる.
- 根から情報源記号にあたる葉まで降りながら割り当てられた数を拾っていく.
例えばについて, , であるとき
Sの2次拡大情報源を3元ハフマン符号化すると次の図のようになる.
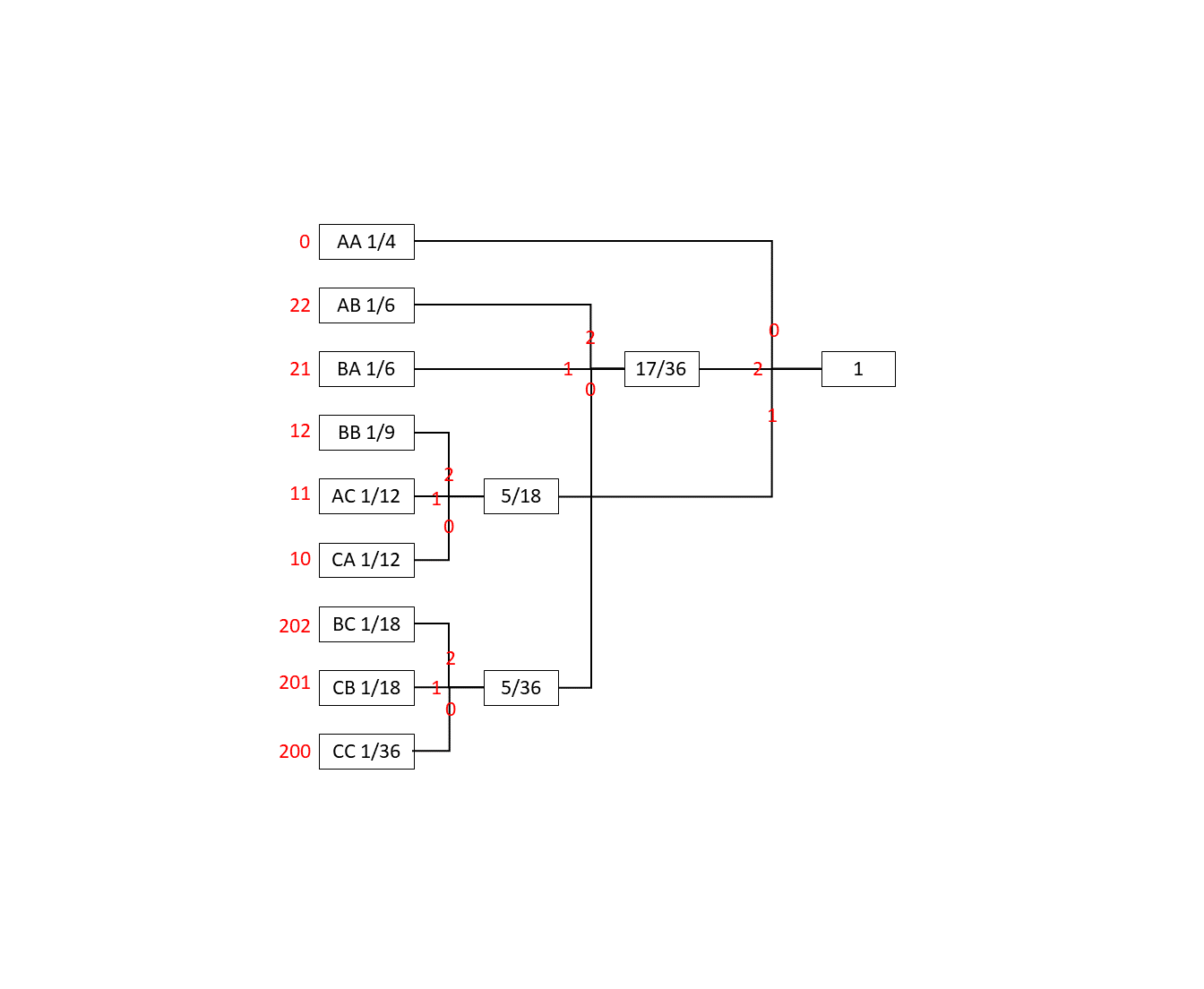
左の赤い数字がハフマン符号にあたる. このハフマン符号の平均長さ(平均符号長)を最小化することでデータが最小限に圧縮できる.
平均符号長は情報源記号の確率を, ハフマン符号の長さをとすると次式で定義される.
つまり, よく出てくる情報源ほど小さい符号長を割り当てたいということである.
エントロピー
Sのエントロピーは情報源iの確率をとして次のように定義される.
Sのエントロピーは平均符号長の下界となる.
実装概要
情報源の数が小さいうちは上図のように手で符号を割り当てられるが, あまりに多いと大変なので計算機に計算させる.
方針としては
- 無記憶情報源Sとn次拡大情報源のn, m元ハフマン符号化のmを入力する.
- 頂点(葉)にあたる構造体を自作する. (部分木の確率の総和と子のリストをもつ.)
- 優先度付きキューを用いて, 確率の小さいm個をとってその親をいれるを繰り返す.
- 根ができれば, 根から深さ優先探索の要領でハフマン符号を取り出していく.
C++による実装例.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| #include <bits/stdc++.h>
using namespace std;
double length = 0;
struct node {
double val = 0;
vector<node> child;
};
bool operator<(const node &a, const node &b) {
return a.val < b.val;
};
bool operator>(const node &a, const node &b) {
return a.val > b.val;
};
void restore(node &a, string &now, vector<string> &ans) {
if (a.child.empty()) {
ans.emplace_back(now);
length += now.size() * a.val;
return;
}
for (int i = 0; i < a.child.size(); i++) {
now += to_string(i);
restore(a.child[i], now, ans);
now.pop_back();
}
}
int main() {
int S_size, n, m;
cin >> S_size >> n >> m;
vector<double> S;
for (int i = 0; i < S_size; i++) {
double u, l;
cin >> u >> l;
S.emplace_back(u / l);
}
vector<double> SE = S;
for (int i = 0; i < n - 1; i++) {
vector<double> temp;
for (auto &j: SE)
for (auto &k: S) temp.emplace_back(j * k);
SE = temp;
}
priority_queue<node, vector<node>, greater<>> tree;
for (auto &i: SE) {
node temp;
temp.val = i;
tree.push(temp);
}
while (1) {
if (tree.size() == 1) {
break;
} else if (tree.size() < m) {
m = tree.size();
}
node temp;
for (int _ = 0; _ < m; _++) {
temp.val += tree.top().val;
temp.child.emplace_back(tree.top());
tree.pop();
}
sort(begin(temp.child), end(temp.child));
tree.push(temp);
}
vector<string> ans;
string now;
node root = tree.top();
restore(root, now, ans);
vector<vector<string>> display(100);
for (auto &i: ans) display[i.size()].emplace_back(i);
for (int i = 0; i < 100; i++) {
sort(begin(display[i]), end(display[i]));
for (auto &j: display[i]) cout << j << endl;
}
cout << length << endl;
}
|
チェック
実装にバグがないか確かめる.
これに先のについて, , についてハフマン符号化していく.
1. Sの2次拡大情報源を3元ハフマン符号化.
エントロピーは
平均符号長は
入力
出力
1
2
3
4
5
6
7
8
9
10
| 0
10
11
12
21
22
200
201
202
1.88889(平均符号長)
|
見事に手計算した先の図とハフマン符号は完全に一致している.
2. Sの3次拡大情報源を2元ハフマン符号化.
平均符号長は
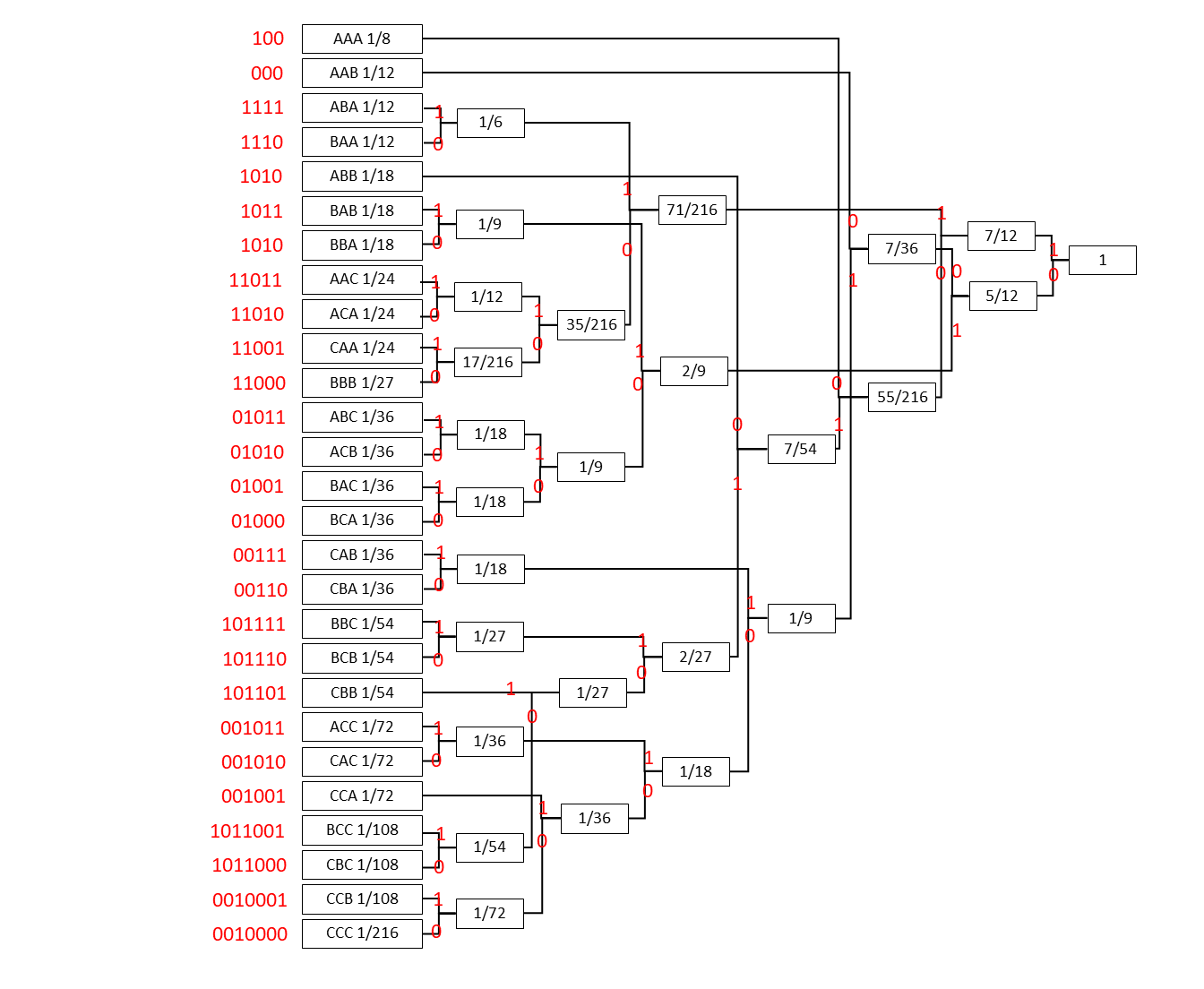
入力
出力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 000
100
0011
0101
0110
1110
1111
00100
00101
01000
01001
01110
10100
10110
11001
11010
11011
011110
101010
101011
101110
101111
110000
0111110
0111111
1100010
1100011
4.41204(平均符号長)
|
3. Sの3次拡大情報源を4元ハフマン符号化.
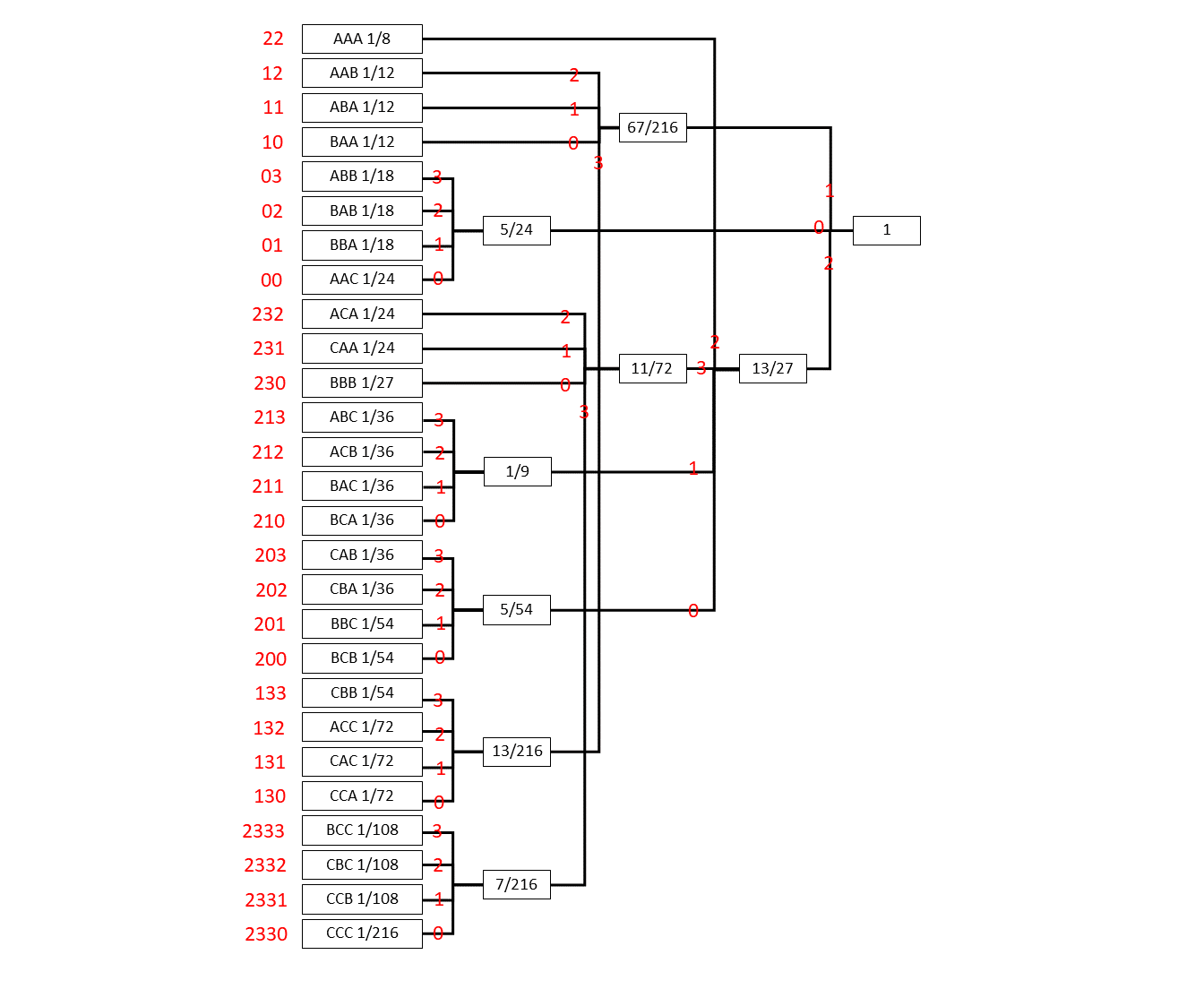
平均符号長
は
入力
出力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 00
01
02
03
11
12
13
22
100
101
102
103
200
201
202
203
210
211
212
213
231
232
233
2300
2301
2302
2303
2.44907(平均符号長)
|